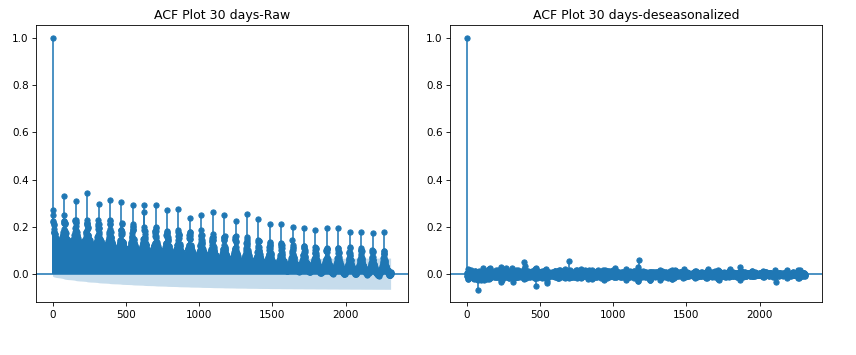
Hi Nick,
do apologize for my late reply!
Thanks a lot for taking the time to share your considerations regarding my problem set. I have skimread sum of these approaches and they seem promising. I will explore them in more detail in due course. Its probably beyond the scope of this project to validate the model with backtest implementations. What i thought about was to simply compare the deviation of the forecasted var-covar matrix from t-1 with the realised var-covar matrix as a percentage…But i can surely discuss some of what you suggested in the outlook section of the thesis.
Let me share my code to forecast the var-covar matrix, Ht. The easiest way is to share all which also includes the original code from Tino with some modifications:
*This is written for a 1 step ahead forecast. For more, an additional looping logic would have to be applied using the last forecasted val…
#starting from after loglike_norm_dcc_copula....
#empty list to capture optimized Qtvals
lastQt=[]`
def dcceq(theta,trdata):
T, N = np.shape(trdata)
a, b = theta
if min(a,b)<0 or max(a,b)>1 or a+b > .999999:
a = .9999 - b
Qt = np.zeros((N, N ,T))
Qt[:,:,0] = np.cov(trdata.T)
global Qbar
Qbar=Qt[:,:,0] #use qbar outside function for forecast
Rt = np.zeros((N, N ,T))
veclRt = np.zeros((T, int(N*(N-1)/2)))
Rt[:,:,0] = np.corrcoef(trdata.T)
for j in range(1,T):
Qt[:,:,j] = Qbar * (1-a-b)
immediatedisturbances=np.matmul(trdata[[j-1]].T, trdata[[j-1]])
Qt[:,:,j] = Qt[:,:,j] + a * immediatedisturbances
Qt[:,:,j] = Qt[:,:,j] + b * Qt[:,:,j-1]
Rt[:,:,j] = np.divide(Qt[:,:,j] , np.matmul(np.sqrt(np.array(np.diag(Qt[:,:,j]), ndmin=2)).T , np.sqrt(np.array(np.diag(Qt[:,:,j]), ndmin=2))))
for j in range(0,T):
veclRt[j, :] = vecl(Rt[:,:,j].T)
#capture last optimized qt value of timeseries
Qt_end = Qt.flatten()
Qt_end=Qt_end[(len(rets)-1)::len(rets)] #syntax: start:stop:step
Qt_end=Qt_end.tolist()
lastQt[0:(numvars**2)]=Qt_end #optimizer loops through function several times, only Qt vector of final and optimum outcome should be used for the forecast
return Rt, veclRt
#this function takes returns, applys a garch model to it with a t distribution, then calls the function garch_t_to_u
model_parameters = {}
udata_list = []
fcast_conditionalvariance_list = []
def run_garch_on_return(rets, udata_list, model_parameters):
for x in rets: #forloop iterates through rets columns
am = arch_model(rets[x], dist = 't', p=1, q=1) #garch(1,1) model with t-distribution
res = am.fit(disp='off') #regression output of tickers in rets df
#uniformly distributed standardized residuals of return series
udata = garch_t_to_u(rets[x], res) #garch t_to_u_function call to change garch t volatility to uniform garch volatility
udata_list.append(udata)
#forecast variance for t+1 / needed for vector Dt in forecastingDCC function
fcastvariance = res.forecast(horizon=1, reindex=False).variance
fcastvariance=fcastvariance['h.1'].iloc[0]
fcast_conditionalvariance_list.append(fcastvariance/optimizerscaling) #scaled back by 1000 as rets are scaled for the optimizer
return udata_list, model_parameters, fcast_conditionalvariance_list
#1.Run Garch on Returns
#2.Estimate dcc theta vals.
#3.Forecast conditional variance of assets
#4.Forecast conditional correlation
#5.Derive forecasted conditional variance-covariance matrix
#1.Run Garch on Returns
udata_list, model_parameters, fcast_conditionalvariance_list = run_garch_on_return(rets.iloc[:,:numvars].dropna(), udata_list, model_parameters)
#2.Estimate dcc theta vals.
#optimizer constraints and bounds
cons = ({'type': 'ineq', 'fun': lambda x: -x[0] -x[1] +1})
bnds = ((0, 0.5), (0, 0.9997))
#minimize loglikelihood
#slsqp algorithm as cons and bnds exist.
%time opt_out = minimize(loglike_norm_dcc_copula, np.array([0.01, 0.95]), args = (udata_list,), bounds=bnds, constraints=cons)
#theta
a,b=opt_out.x
#3.Forecast conditional variance of assets
#variances for variance-covariance matrix-needed for VaR. Needed for Matrix Dt. Careful, Matrix Dt requires vol not variance
fcast_conditionalvariance_list
Dt=np.sqrt(np.diag(np.array(fcast_conditionalvariance_list)))
#4.Forecast conditional correlation, Rt
listoflists=[]
for i in range(0, len(lastQt), numvars):
listoflists.append(lastQt[i:i+numvars])
lastQt=np.array(listoflists)
fcast_immediatedisturbances=np.zeros((numvars,numvars))
Qtforecast=Qbar * (1-a-b) + a * fcast_immediatedisturbances + b * lastQt
Qtforecast = np.reshape(Qtforecast, (numvars,numvars))
Rtforecast = np.divide(Qtforecast , np.matmul(np.sqrt(np.array(np.diag(Qtforecast), ndmin=2)).T , np.sqrt(np.array(np.diag(Qtforecast), ndmin=2))))
#5.Derive forecasted conditional variance-covariance matrix, Htforecast
Htforecast=np.matmul(np.matmul(Dt, Rtforecast),Dt)
I should have named Dt to Dtforecast aswell for proper measure aswell as using fcast here, and forecast there…I do apologize.
Your exploration of different copulas also looks very interesting. Unfortunatly, I havent had the time to look into that in great enough debth!
Kind regards,
Toni